Le blog
Catégories :
Toutes les catégories
Algorithmique
C++
Cocoa & Objective-C
Général
Nubo
Xcode
Zinc
Abonnement
RSS
Bonnes pratiques C++ (5/n)
Publié le 03 Oct 2021 dans C++.
Ce billet appartient à une série consacrée aux bonnes pratiques de développement C++. Certains sont toutefois applicables à d'autres langages. Aujourd’hui : l’architecture logicielle.
Raisonnez par couches
Il n’est pas question de faire ici un cours théorique d’architecture, mais il est bon de rappeler quelques principes de base. Et pour commencer, il faut tordre le cou à une croyance beaucoup trop répandue : celle de croire que votre code est modulaire juste parce qu’il est organisé en petits modules bien rangés dans des répertoires séparés.
En réalité, si chacun des n modules à besoin de pratiquement tous les n-1 autres modules, alors vous avez en réalité un code monolithique. Aucun module ne peut être extrait et réutilisé ailleurs, aucun module ne peut être compris sans une compréhension minimale préalable de tous les autres modules, et faire évoluer l’un des modules nécessite souvent des modifications dans plusieurs autres modules éloignés (ce qui viole un certain nombre de principes d’architecture et de programmation objet). Il n’est pas aisé non plus de remplacer un module par un autre de fonctionnalité équivalente, comme changer le moteur de base de données : il y a trop de dépendances partout. Un tel projet est difficile à comprendre, à maintenir et même, à compiler, parce qu’il existe des dépendances circulaires entre les différents modules, et cette difficulté à écrire le makefile est déjà le signe d’un problème.
Pour éviter ce piège du code faussement modulaire, il est utile de raisonner par couches logicielles. L’idée est d’organiser les classes et les modules en différents niveaux, suivant leur degré de spécialisation.
- Les couches basses sont les plus généralistes. Elles s’occupent typiquement de l’accès aux données (lecture et écriture de fichiers, conversions de formats, etc.), de l’interfaçage avec le monde extérieur (composants graphiques, appels à des web services, connexion à des bases de données, entrées/sorties sur la console, etc.) ou encore de fonctionnalités généralistes utilisées partout (routines de gestion d’erreur, fonctions mathématiques, conversions d’unités, etc.) Ce sont des modules non spécialisés : ils sont réutilisables tels quels dans d’autres projets et d’ailleurs, si vous avez un peu de bouteille, vous avez probablement sur votre disque dur un répertoire rempli de ces classes utilitaires, prêtes à servir, que vous pouvez coller dans n’importe quelle application.
- Les couches hautes, en revanche, sont les plus spécialisées. Elles contiennent les modules qui implémentent spécifiquement l’application. Il n’y aurait donc aucun sens à vouloir les réutiliser ailleurs, dans une application différente. Il peut s’agir d’écrans, de boîtes de dialogue, d’intelligence métier, de lecture et d’écriture de fichiers dans un format propriétaire et surtout, du code qui orchestre et coordonne le fonctionnement de tout ces éléments ensemble.
- En fonction des besoins, il est aussi possible de définir des couches intermédiaires, qui contiennent des modules mi-généralistes, mi-spécialisés. Par exemple, il peut s’agir d’un module appelant un web service particulier ; ça peut resservir dans n’importe quelle autre application ayant besoin d’appeler le même web service, mais c’est déjà une fonctionnalité d’assez haut niveau qui s’appuie sur d’autres modules encore plus généralistes, tels qu’un parseur JSON et un module HTTP, qui lui-même va s’appuyer sur d’autres modules encore plus généralistes comme les fonctions socket et une bibliothèque de cryptographie.
Une fois l’application ainsi structurée en couches, les deux règles à respecter impérativement (et je ne saurais jamais insister assez sur ce caractère impératif !) sont les suivantes :
- Un module situé dans une couche ne peut appeler que des fonctions implémentées dans les couches inférieures (ou plus rarement dans la même couche), mais ne peut jamais appeler de fonctions situées dans les couches supérieures.
- Un module situé dans une couche ne doit faire aucune supposition sur la façon dont il va être utilisé par les couches supérieures.
Pour rendre tout ceci plus clair et surtout plus concret, imaginons une application pour smartphone typique, qui implémente quelques écrans, qui stocke des données dans une base locale, et qui interagit avec un serveur distant via une API REST. Un tel logiciel peut s’organiser de la façon suivante :
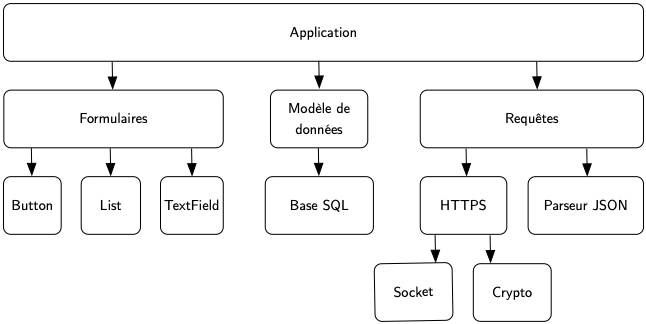
Au niveau le plus haut, on a la couche applicative. C’est la partie la plus spécifique, elle implémente cette application proprement dite. Elle coordonne essentiellement le fonctionnement de tous les autres modules : affichage des écrans dans le bon ordre et en réponse aux actions de l’utilisateur, accès à la base de données, appels au monde extérieur, etc.
Plus bas à gauche se trouve la partie UI. Il s’agit de classes implémentant les différents écrans et boîtes de dialogue qui composent l’application, classes qui s’appuient elles-mêmes sur des composants graphiques élémentaires tels que des boutons, des listes, des champs éditables, etc. Certains de ces composants peuvent d’ailleurs être fournis par le système ou par des bibliothèques tierces.
Au centre se trouve la partie qui gère le stockage local. Elle se décompose en deux niveaux : le modèle de données, qui contient les classes représentant les objets manipulés par l’application (un utilisateur, un article, un panier d’articles, etc.) et qui fournit des méthodes pour agir dessus ; et le stockage proprement dit, sous la forme d’une base de données SQL.
À droite se trouve l’appel au web service. Il se compose d’une ou plusieurs classes implémentant les différentes requêtes possibles, qui elles-mêmes s’appuient sur deux modules, l’un pour l’encodage et le décodage des données au format JSON et l’autre pour effectuer la requête HTTP proprement dit, qui s’appuie lui-même sur la couche sockets et sur une bibliothèque de cryptographie.
Les deux règles édictées plus haut s’appliquent parfaitement à cet exemple. Les couches supérieures appellent des fonctions dans les couches inférieures : l’application va appeler des méthodes permettant d’afficher les écrans, qui eux-mêmes vont appeler des méthodes permettant de dessiner des boutons, des listes et autres composants graphiques ; l’application va agir sur les classes métier qui elles-mêmes vont traduire ces opérations en requêtes SQL envoyées à la base de données, etc. Il n’y a jamais d’appels directs dans l’autre sens. Et d’autre part, chaque couche ne fait aucune supposition sur la façon dont elle va être utilisée par les couches supérieures : un bouton ne fait aucune supposition sur l’aspect ou le comportement de la page où il va être affiché, la base SQL ne fait aucune supposition sur les requêtes qu’elle va recevoir, le parseur JSON ne fait aucune supposition sur le contenu des données qu’il va devoir analyser, etc.
Ce type d’architecture présente de nombreux avantages.
- La séparation des rôles. Chacune des classes ne fait qu’une seule et unique tâche élémentaire. Elles sont donc simples à implémenter, simples à tester et surtout, simples à relire et à faire évoluer. C’est le point le plus important et s’il n’y avait qu’une seule chose à retenir, ce serait celle-ci : chaque classe ne doit implémenter qu’une seule tâche. (On en reparlera dans un prochain chapitre.)
- La réutilisabilité. Les couches basses ne sont pas spécifiques à l’application et peuvent resservir dans d’autres projets sans modification, ou presque. Cette réutilisabilité était une grande promesse de la programmation objet lorsqu’elle s’est généralisée dans les années 80 ; et ce fut aussi une grande source de déception, lorsque beaucoup découvrirent que leur code n’était pas aussi réutilisable qu’espéré ! C’est qu’en réalité, plus que la programmation objet, ce sont surtout les bons choix d’architecture qui apportent la réutilisabilité.
- La testabilité. Beaucoup de classes, surtout dans les couches basses et intermédiaires, implémentent des comportements élémentaires faciles à valider dans des tests unitaires. Par exemple : le parseur JSON, la classe qui transforme les opérations métier en requêtes SQL, les fonctions de localisation des chiffres et des dates, les fonctions de cryptographie, etc. Avoir des briques de bases bien testées est un bon début pour construire des choses solides au-dessus.
- La localité. À la différence d’un code monolithique où tout dépend de tout, les classes d’une application correctement architecturée ne dépendent chacune que d’un nombre limité d’autres classes, à savoir les classes sur lesquelles elles s’appuient dans les couches inférieures. Pour comprendre un bout de code, il suffit donc de s’intéresser au code localement, au pire au code des modules voisins. Il n’est pas nécessaire de s’intéresser à l’ensemble de l’application. Ceci est d’autant plus vrai que beaucoup de classes peuvent être considérées comme des boîtes noires : pas besoin de comprendre en détail comment est implémenté un composant graphique ou une base SQL pour l’utiliser. Cela simplifie la maintenance. De plus, avoir un couplage aussi faible que possible entre modules limite le risque d’effet de bord lors d’une modification.
Une autre façon de voir les choses est de s’intéresser au trajet d’une donnée. Dans l’application décrite ci-dessus, imaginons le trajet du prix d’un article, depuis la base de données jusqu’à l’utilisateur. (Sur ce schéma, les couches les plus élevées sont à gauche et les couches basses à droite.)

Au bout de la chaine se trouve l’utilisateur. Il voit s’afficher un prix dans la devise et au format correspondant à son pays, par exemple £1.23 ou $1.70 ou encore 1,45 €. Cette mise en forme est effectuée par la couche UI (éventuellement en s’appuyant sur des fonctions accessoires de formatage situées dans les couches basses). Cette couche UI extrait cette valeur des couches métier sous la forme d’un type de données facile à manipuler par la machine, tel que int ou double : il est aisé de faire des opérations dessus, comme appliquer un pourcentage de réduction ou additionner le prix de plusieurs articles. Enfin, la couche métier extrait elle-même ces informations d’une base de données, grâce à une requête SQL.
La séparation des rôles est ici bien apparente. Chaque classe n’accomplit qu’une opération basique de conversion ou de mise en forme, ignore ce que font les autres classes autour, et ne fait aucune supposition sur la façon dont elle est utilisée. Cela permet d’écrire du code simple à chaque étape, alors que dans le cas contraire, si par exemple la construction et l’exécution de la requête SQL ainsi que la mise en forme du prix étaient effectuées directement dans la couche UI, le code de cette couche deviendrait très complexe et sa logique serait en quelque sorte « polluée » par des détails techniques. Il est bien plus simple et direct d’écrire (et surtout de relire) :
double price = article.getPrice(); std::string str = currentUser.GetLocale().formatPrice(price); label.setText(str);
Que :
int query = sql_prepare_query(
"SELECT price FROM articles WHERE article_id=%id"
);
sql_bind(query, "%id", article);
sql_step(query);
double price = sql_column_double(query, 0);
sql_finalize(query);
std::ostringstream oss;
oss.imbue(currentUser.getLocale());
std::string locale = currentUser.getLocale().name();
if (locale == "fr_FR") {
oss << std::setprecision(2) << price << " €";
} else if (locale == "en_GB") {
oss << "£" << std::setprecision(2) << price;
} else if (locale == "en_US") {
oss << "$" << std::setprecision(2) << price;
}
label.setText(oss.str());
(Et encore, le code ci-dessus ne contient aucune gestion d’erreur ! Un exemple réaliste serait bien pire et malheureusement, pas si caricatural : je croise régulièrement ce genre de chose dans du code en production.)
Un autre avantage à avoir une séparation des rôles aussi nette est que si vous devez un jour changer de moteur de base de données, ou bien supporter d’autres devises, vous n’aurez à faire que quelques adaptations dans les couches basses, et non des modifications disséminées dans toute l’application.
À ce stade, un détail devrait vous intriguer : si les couches basses ne peuvent jamais appeler les couches hautes, comment un bouton peut-il prévenir la page sur laquelle il se trouve que l’utilisateur a cliqué dessus ? Comment le parseur JSON peut-il prévenir la classe qui l’utilise qu’elle a rencontré une erreur de syntaxe ? Comment l’objet socket peut-il prévenir l’objet HTTP que des données sont disponibles et attendent d’être lues ? Ce problème s’appelle l’inversion de contrôle et il est essentiel pour au moins une raison : le code des couches basses réside souvent dans le système d’exploitation lui-même (cas des composants graphiques ou de la couche réseau) ou dans des bibliothèques tierces (cas des parseurs, des bases de données, de la cryptographie, etc.) et par définition ce code externe ne peut pas appeler le vôtre directement puisqu’il ignore tout de son existence.
Les trois principales manières d’implémenter l’inversion de contrôle sont les suivantes. (Il existe bien sûr des variantes.)
Les callbacks. Lorsque vous créez un composant, vous lui passez un pointeur sur une fonction et dès qu’un événement survient, cette fonction est appelée. Beaucoup de bibliothèques graphiques utilisent ce pattern ; par exemple, pour créer une fenêtre avec l’API historique de Windows, il faut passer un pointeur sur la fonction qui traitera les événements survenant dans cette fenêtre (mouvements de la souris, appuis sur les touches de clavier, redimensionnement, fermeture, etc.). Les slots et les signaux de Qt ne sont qu’une encapsulation de ce principe dans un modèle conceptuel de plus haut niveau.
La délégation. Il s’agit d’un design pattern fréquent en C++, qui fonctionne sur le même principe que la callback ; sauf qu’au lieu de passer un pointeur sur une fonction, vous passez un pointeur sur un objet qui implémente des méthodes définies à l’avance grâce à une interface. Par exemple :
class IButtonDelegate {
public:
virtual void onClick(Button * sender) = 0;
};
class Button {
public:
Button(IButtonDelegate * delegate);
// autres méthodes omises par souci
// de brièveté
};
Pour utiliser un tel composant, votre code n’a qu’à implémenter une classe concrète dérivant de IButtonDelegate et à passer une instance de cette classe au constructeur de Button. Chaque fois que l’utilisateur cliquera sur le bouton, ce dernier vous notifiera en appelant la méthode onClick de l’objet que vous lui avez passé.
Toute la couche graphique de macOS et d’iOS fonctionne sur ce principe de délégation et d’implémentation d’interface abstraite. (À la différence que le langage utilisé est Swift plutôt que C++, mais le principe reste identique.)
La queue de messages. Le système fournit une file d’attente et des méthodes pour y poster et en extraire des messages. Lorsqu’un composant de bas niveau doit notifier les couches supérieures, il poste un message dans la queue ; de son côté, l’application implémente une boucle infinie, qui extrait les messages de la queue au fur et à mesure pour les dispatcher aux différents modules, généralement par un système de callbacks. Toute la couche graphique de Windows fonctionne sur ce principe. (En réalité, les autres interfaces graphiques aussi, mais de façon interne et non visible pour le code utilisateur. Il y a une bonne raison à cela : c’est une architecture qui permet de gérer les événements asynchrones, ce qui est par essence le cas des événements souris ou clavier dans une interface graphique.)
En pratique, comment s’astreindre à ces beaux principes d’architecture ? C’est simple : implémentez chaque couche logicielle sous la forme d’une bibliothèque (ou du moins pensez-la comme tel, même si ce n’est techniquement pas une véritable bibliothèque.) Imaginez que vos classes vont être utilisées par un autre développeur, dans un projet dont vous ignorez tout et d’une façon dont vous ne pouvez rien savoir. Cela n’a rien d’insurmontable : c’est très précisément l’exercice auquel se livrent les développeurs qui conçoivent les systèmes d’exploitation ou les bibliothèques de composants graphiques !